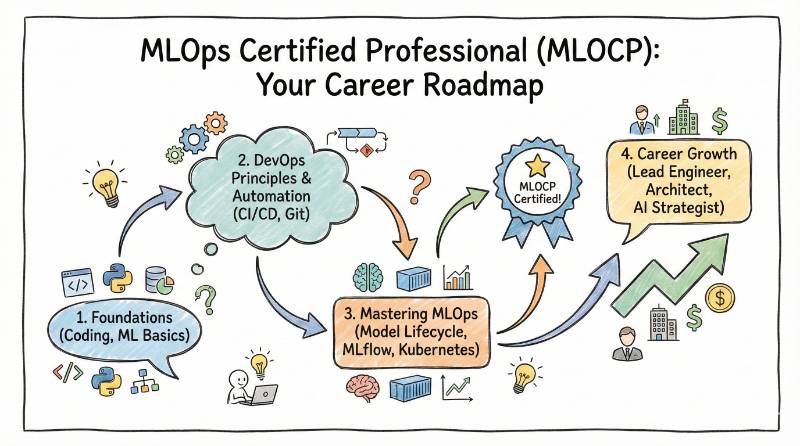
Introduction
We have entered the era of “Software 2.0,” where logic is learned from data rather than just written by humans. Yet, a critical problem remains: building a model is easy; keeping it alive in production is hard. Too many organizations are stuck in the “POC Trap.” They have brilliant machine learning models sitting in Jupyter Notebooks that never deliver value to real users. Why? Because the infrastructure to deploy, monitor, and scale these models is missing. This is where MLOps (Machine Learning Operations) steps in. MLOps is not just a buzzword; it is the disciplined engineering practice of unifying ML system development (Dev) and ML system operation (Ops). It bridges the gap between the chaotic experimentation of data science and the rigid reliability of software engineering. The MLOps Certified Professional (MLOCP) program is designed for engineers and leaders who want to solve this problem. It is the roadmap to becoming the architect who doesn’t just build models, but builds the systems that make AI reliable, scalable, and valuable.
MLOps Certifications at a Glance
Navigating certifications can be confusing. To simplify your journey, I have broken down the relevant certifications in this ecosystem. Most professionals should aim for the Professional level, but leaders may start with the Foundation.
| Certification Track | Level | Who it’s for | Prerequisites | Skills Covered | Recommended Order |
|---|---|---|---|---|---|
| MLOps Foundation | Beginner | Managers, QA Leads, Project Managers, Business Analysts | Basic IT awareness, understanding of SDLC | MLOps terminology, Lifecycle management, Model Governance, Basic CI/CD concepts | 1 |
| MLOps Certified Professional (MLOCP) | Advanced | DevOps Engineers, Data Scientists, SREs, Backend Developers | Linux CLI, Docker, Python basics, Git | End-to-end Pipelines, Model Registry, Drift Detection, Kubernetes, Feature Stores | 2 |
| SRE Certified Professional (SRECP) | Expert | Senior Engineers, Tech Leads, Operations Managers | Scripting, System Design, Monitoring | Reliability Engineering, SLOs/SLIs, Incident Management, Observability | 3 |
What it is
The MLOCP is a rigorous, hands-on certification program that validates your ability to architect, build, and manage the entire machine learning lifecycle.
It moves beyond the theory of “what is AI” and focuses entirely on the “plumbing” required to make AI work in the real world. It teaches you how to treat ML models as robust software artifacts—ensuring they are reproducible, scalable, and reliable when serving millions of users.
Who should take it
- DevOps Engineers: You are already handling code pipelines; this course teaches you how to handle the unique constraints of data pipelines and model artifacts (which are much larger and more fragile than compiled binaries).
- Data Scientists: You are tired of handing off your models to engineering teams only to see them fail or take months to deploy. You want to own the deployment process end-to-end.
- SREs: You are responsible for the reliability of AI-driven applications and need to understand how to monitor “probabilistic” software that can degrade even when the server is up.
- Platform Engineers: You are tasked with building an Internal Developer Platform (IDP) for your data science team and need to know the architectural patterns for self-service training and deployment.
Skills you’ll gain
- Containerization for ML: You will learn to master Docker specifically for ML—handling massive libraries (PyTorch/TensorFlow), optimizing image sizes to reduce startup time, and managing GPU pass-through in containers.
- Orchestration & Serving: You will learn how to deploy models not just as scripts, but as scalable microservices on Kubernetes. You will use tools like KServe or Seldon Core to manage traffic and autoscaling.
- Pipeline Automation (CT/CD): You will build “Continuous Training” pipelines. When data changes, the pipeline should automatically trigger, retrain the model, evaluate it, and potentially redeploy it without human intervention.
- Model Registry Management: You will learn to treat models as versioned artifacts using MLflow. This ensures you can always answer the question: “Which dataset trained the model that is currently running in production?”
- Drift Detection: You will implement monitoring systems using Prometheus and Grafana that alert you when “Data Drift” (input data changes) or “Concept Drift” (world changes) occurs, so you can retrain before business value is lost.
- Feature Stores: You will understand how to manage and serve features consistently between training (batch) and inference (real-time) to avoid “training-serving skew,” a common cause of model failure.
Real-world projects you should be able to do after it
- Project 1: The Scalable Inference API
- Goal: Take a raw Python model and wrap it in a high-performance FastAPI wrapper.
- Outcome: Dockerize the application, push it to a registry, deploy it to a Kubernetes cluster, and configure a Load Balancer to handle traffic spikes.
- Project 2: The “Hands-Off” Retraining Pipeline
- Goal: Build a Jenkins or GitLab CI pipeline that watches a data source (like an S3 bucket).
- Outcome: When a new dataset arrives, the system automatically spins up a training job, evaluates the accuracy against a baseline, and if the new model is better, registers it for deployment.
- Project 3: The Observability Dashboard
- Goal: Create a Grafana dashboard that visualizes not just system metrics (CPU/RAM) but model health metrics.
- Outcome: Live graphs showing “Prediction Confidence,” “Input Null Rates,” and “Inference Latency,” with alerts configured for anomalies.
Preparation plan
- 7–14 Days (Fast Track – For Experienced DevOps)
- Focus intensively on Docker and Python (Flask/FastAPI).
- Build one simple end-to-end API: Train a toy model, wrap it, containerize it, and run it locally.
- Skip complex orchestration tools like Kubeflow for now; focus on the core workflow.
- 30 Days (Standard – Recommended)
- Week 1: Foundations. Linux networking, Git strategies for data (DVC), and Python scripting.
- Week 2: Packaging & Serving. Deep dive into Docker optimization and API development.
- Week 3: Pipeline Orchestration. Connect the dots using Jenkins or GitHub Actions to automate the workflow.
- Week 4: Operations. Focus on Monitoring, logging, and drift detection. Practice the capstone project.
- 60 Days (Deep Dive – For Beginners)
- Month 1: Spend the entire first month mastering the tools individually: Python, Docker, and Kubernetes basics. Do not rush the fundamentals.
- Month 2: Focus on the integration of these tools into MLOps workflows. Build the full capstone projects from scratch without looking at tutorials.
Common mistakes
- Treating Models like Code: Code is deterministic; models are probabilistic. Failing to version the data used to train the model makes reproducibility impossible.
- Ignoring the Data: Deploying a model and assuming it will stay accurate forever. Without drift detection, your model will silently fail as the world changes.
- Over-Engineering: Trying to implement massive enterprise tools (like Kubeflow) when a simple Python script and a Cron job would suffice for the scale of the problem.
- Security Gaps: Leaving model endpoints exposed without authentication, or hardcoding API keys in training scripts (a major security risk).
Best next certification after this
SRE Certified Professional (SRECP).
Once you can build the system (MLOps), you need to ensure it never goes down (SRE). This combination makes you a “Full Stack” Infrastructure Engineer who can both ship features and guarantee uptime.
Choose Your Path
The technology field is vast. Here is how MLOps fits into the six major career tracks:
- DevOps Path
- Focus: CI/CD, Infrastructure as Code, Automation.
- Why MLOps? It is the next frontier of DevOps. You are applying your existing skills to a new, high-demand domain.
- DevSecOps Path
- Focus: Security, Compliance, Governance.
- Why MLOps? “Adversarial Machine Learning” is real. You need to secure the model supply chain and prevent data poisoning.
- SRE Path
- Focus: Reliability, Scalability, Uptime.
- Why MLOps? AI models are heavy, resource-intensive, and prone to latency. SRE skills are vital to keep them running efficiently.
- AIOps/MLOps Path
- Focus: The intersection of AI and Operations.
- Why MLOps? This IS the path. You are the specialist who bridges the gap between data scientists and cloud infrastructure.
- DataOps Path
- Focus: Data Pipelines, ETL, Data Quality.
- Why MLOps? MLOps is essentially “DataOps + Model Training.” If you can move data reliably, moving models is the next logical step.
- FinOps Path
- Focus: Cloud Cost Optimization.
- Why MLOps? GPU compute is incredibly expensive. An expert who can optimize AI training costs and inference architecture is worth their weight in gold.
Role → Recommended Certifications Mapping
| Role | Primary Certification | Secondary / Extension Certification |
|---|---|---|
| DevOps Engineer | Master in DevOps (MDE) | MLOps Certified Professional (MLOCP) |
| Site Reliability Engineer | SRE Certified Professional (SRECP) | Certified Kubernetes Administrator (CKA) |
| Platform Engineer | MLOps Certified Professional (MLOCP) | Terraform Associate |
| Cloud Engineer | AWS/Azure Solutions Architect | MLOps Certified Professional (MLOCP) |
| Security Engineer | Certified DevSecOps Professional | MLOps Certified Professional (MLOCP) |
| Data Engineer | MLOps Certified Professional (MLOCP) | Spark / Databricks Certifications |
| FinOps Practitioner | FinOps Certified Practitioner | MLOps Certified Professional (MLOCP) |
| Engineering Manager | MLOps Foundation | Scrum Master / Agile Certification |
Top Institutions for MLOps Training
Finding the right training partner is critical. Here are the top institutions that offer “Training cum Certification” for this program:
- DevOpsSchool
As the official provider of the MLOCP certification, DevOpsSchool is the gold standard for this specific track. They offer a comprehensive curriculum that balances theory with rigorous hands-on labs, ensuring you don’t just pass the exam but actually learn to build production-grade ML pipelines. Their program includes lifetime access to learning materials (LMS) and community support, which is invaluable for long-term career growth. - Cotocus
Cotocus is widely recognized for its corporate training and consulting-led approach. Their instructors are typically working consultants who bring deep, real-world project experience into the classroom, making their training ideal for teams that need to solve actual business problems. They excel at customizing the MLOCP curriculum for specific industry needs, such as finance or healthcare. - Scmgalaxy
For those who prefer a community-driven learning environment, Scmgalaxy is an excellent resource. They provide a vast library of tutorials, forums, and peer-to-peer support that complements formal training. It is a great place to troubleshoot specific toolchain issues (like Jenkins or Docker errors) while preparing for your certification. - BestDevOps
BestDevOps focuses on high-impact, intensive bootcamp-style training designed for professionals who need to upskill quickly. Their courses are often structured as fast-track weekend batches, making them perfect for working engineers who have limited time but high motivation to clear the MLOCP certification efficiently. - devsecopsschool
If your focus is on the security and governance aspect of AI, devsecopsschool is the premier choice. They tailor the MLOCP curriculum to emphasize “shifting left” in ML pipelines—teaching you how to secure model artifacts, manage secrets, and ensure compliance, which is critical for highly regulated industries. - sreschool
This institution approaches MLOps from a Site Reliability Engineering (SRE) perspective. Their training places a heavy emphasis on the “Ops” side—monitoring, service level objectives (SLOs), and incident response for AI models. It is the ideal training partner if your goal is to ensure the reliability and uptime of production ML services. - aiopsschool
A highly specialized provider, aiopsschool focuses strictly on the intersection of Artificial Intelligence and IT Operations. Their deep dive into AI-specific tooling makes them a great choice for advanced practitioners who want to go beyond the basics and master complex orchestrators like Kubeflow alongside the standard MLOCP syllabus. - dataopsschool
Tailored specifically for Data Engineers, dataopsschool bridges the gap between traditional data warehousing and modern MLOps. Their training highlights data lineage, quality validation, and pipeline automation, ensuring that the “data” part of your MLOps workflow is just as robust as the “model” part. - finopsschool
With the rising cost of AI compute, finopsschool offers a unique angle on MLOps training. They focus on the financial operations aspect—teaching you how to architect ML systems that are not only effective but also cost-efficient. This is increasingly important for leaders and architects who need to manage cloud budgets for expensive GPU workloads.
Next Certifications to Take
Once you have mastered the MLOCP, keep your momentum going with these strategic options:
- Same Track (Deepen Expertise): Advanced AI Engineering. Go deeper into specific domains like Large Language Model Operations (LLMOps) and Generative AI pipelines.
- Cross-Track (Broaden Skills): SRE Certified Professional (SRECP). This is the perfect complement, adding “Reliability” to your “Operations” skillset.
- Leadership (Management): Master in DevOps Engineering (MDE). Step up to architect entire organizational delivery systems, managing both code and data lifecycles.
FAQs regarding Career & Certification
1. How difficult is the MLOCP exam?
It is intermediate to advanced. It requires a solid grasp of Linux and containerization. If you are new to infrastructure, expect a steeper learning curve than a pure coding exam.
2. How much time does it take to prepare?
For a working professional, expect to dedicate about 4–6 weeks (approx. 40 hours) of study and hands-on lab time to be fully ready.
3. Do I need to be a Data Scientist first?
No. You need to understand the lifecycle of a model (training, validation, inference), but you do not need to know the complex math behind the algorithms or how to design neural networks.
4. Is coding required?
Yes. You need intermediate skills in Python (for scripting and APIs) and familiarity with Bash/Shell scripting for automation.
5. What is the value of this certification in the market?
Very high. There is a massive talent shortage of engineers who can actually deploy models. Data Scientists are common; MLOps engineers are rare and highly paid.
6. Can I take this if I am a fresher?
Yes, but you will need to work much harder on the foundational skills (Linux, Networking, Git) that experienced engineers already possess.
7. Does this cover Large Language Models (LLMs)?
The core principles (versioning, containerization, pipelines) are identical. Specific LLMOps tools are an advanced extension of this foundation.
8. What is the passing score?
Typically around 65-70%, though this depends on the specific exam version administered by DevOpsSchool.
9. Is the exam practical or multiple choice?
It is a mix, but the training places a heavy emphasis on practical, project-based assessments to ensure you can “do” the work.
10. Do I need a cloud account?
Yes. You will need a free-tier account on AWS, Azure, or Google Cloud to practice deploying your models to a real environment.
11. How does this differ from “Data Engineering”?
Data Engineering focuses on moving data to the model. MLOps focuses on moving the model to production and keeping it alive there.
12. Will this help me become an SRE?
Yes. It provides a specialized skillset that is increasingly demanded in SRE roles at AI-first companies.
FAQs (8 Q&A) on MLOps Certified Professional (MLOCP)
1. What is the duration of the training?
The training is approximately 30-35 hours, covering both theoretical concepts and extensive hands-on labs.
2. Is the training live or recorded?
DevOpsSchool offers both Live Instructor-led sessions (weekend/weekday) and Self-paced video modes to suit your schedule.
3. What projects will I work on?
You will work on real-time industry projects, such as building a scalable House Price Prediction system with a full CI/CD pipeline.
4. Is technical support provided?
Yes, Lifetime Technical Support is provided. You can reach out for help with labs or projects even after the course ends.
5. Do I get access to course materials?
Yes, you get Lifetime LMS access, which includes class recordings, PDF slides, interview kits, and future updates.
6. Can I get a group discount?
Yes, discounts are generally available for groups of 2 or more (often 10% off), with higher discounts for larger corporate groups.
7. Is placement assistance provided?
Yes, the program includes an Interview Preparation Kit, mock interviews to test your readiness, and resume guidance.
8. What if I miss a live class?
You can watch the class recording in the LMS or attend the missed session in the next available batch within 3 months at no extra cost.
Conclusion
The shift from just building models to running them in the real world is the biggest challenge tech teams face today. It is no longer enough to have a smart AI experiment on a laptop; companies need systems that work reliably for millions of users, day after day. The MLOps Certified Professional (MLOCP) program is your roadmap to solving this problem. It proves you have the practical skills to build the “factory” that delivers AI safely and efficiently. By mastering these tools now, you are securing your place as a vital expert in the future of software engineering.