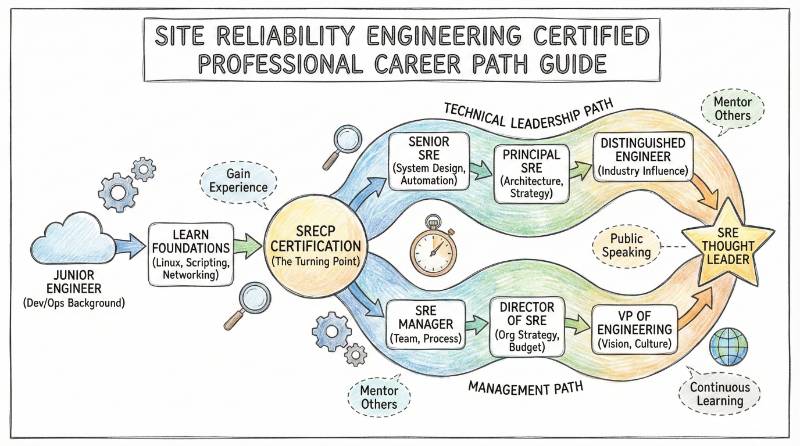
Introduction
In the modern software landscape, “It works on my machine” is no longer an acceptable defense. Systems must work in production, at scale, under pressure, and without downtime. This is where Site Reliability Engineering (SRE) steps in. It is not just a buzzword; it is the discipline of treating operations as a software problem. For working engineers and managers, mastering SRE is the single most effective way to future-proof a career. The Site Reliability Engineering Certified Professional (SRECP) is designed to bridge the gap between theory and real-world application. It transforms traditional SysAdmins and DevOps Engineers into reliability experts who can speak the language of Error Budgets, SLIs, and SLOs with confidence. This guide covers everything you need to know about the SRECP certification—from the syllabus and skills to the career outcomes.
Certification Snapshot
| Feature | Details |
|---|---|
| Certification Name | Site Reliability Engineering Certified Professional (SRECP) |
| Track | SRE / DevOps / Operations |
| Level | Intermediate to Advanced |
| Who it’s for | DevOps Engineers, System Administrators, Operations Managers, Software Engineers |
| Prerequisites | Basic knowledge of Linux, Networking, and Software Development Life Cycle (SDLC) |
| Skills Covered | SLI/SLO/SLA management, Error Budgets, Observability (Prometheus/Grafana), Automation, Incident Response |
| Recommended Order | Take after mastering basic DevOps or Linux Administration |
| Official Link | SRE Certified Professional (SRECP) |
| Provider | DevOpsSchool |
Deep Dive: Site Reliability Engineering Certified Professional (SRECP)
What it is
The SRECP is an advanced training and certification program designed to equip you with the deep operational knowledge required to build scalable, reliable, and secure systems . Unlike generic courses that only teach you how to install a tool, this program focuses on the methodology of reliability—combining 69+ hours of rigorous training with real-world implementation strategies used by top tech companies.
Who should take it
- DevOps Engineers looking to specialize in reliability and observability.
- Operations Leaders aiming to implement SRE culture in their teams.
- Software Engineers who want to own their code in production.
- System Administrators transitioning into modern cloud-native roles.
Skills you’ll gain
- Core SRE Principles: Defining and implementing Service Level Indicators (SLIs), Service Level Objectives (SLOs), and Error Budgets to balance speed with stability .
- Observability Stack: Mastery of Prometheus (Metrics collection, PromQL) and Grafana (Visualization, Dashboards, Alerting).
- Automation & Scripting: Linux Shell Scripting and automation strategies to eliminate “toil” (manual, repetitive work).
- Performance Engineering: Using JMeter for performance testing, bottleneck analysis, and capacity planning.
- Incident Management: Structured approaches to alerting, on-call rotations, and root cause analysis.
- Cloud Native Tooling: Practical exposure to Kubernetes, Nginx, and Secret Storage for securing production environments.
Real-world projects you should be able to do after it
Upon completion, you will be able to execute projects such as:
- Designing a Reliability Framework: Creating a complete SLI/SLO document for a microservices application and negotiating error budgets with product owners.
- Building a Monitoring Dashboard: Setting up a Prometheus and Grafana stack to monitor critical infrastructure metrics and visualizing data in real-time.
- Automating Incident Response: Configuring alert rules that distinguish between genuine incidents and noise, reducing team fatigue.
- Chaos Engineering Implementation: Simulating failure scenarios to test system resilience and recovery speeds.
The Strategic Preparation Plan (60 Days)
For working professionals, cramming rarely works for a certification of this depth. This 60-day roadmap allows for 1 hour of study per day, ensuring you truly master the concepts rather than just memorizing them.
Phase 1: The Strong Foundation (Days 1–15)
Focus: Linux, Scripting, and the “Why” of SRE.
- Days 1–5 (Linux Internals): Don’t just learn commands; learn how the kernel handles processes, memory, and I/O. Task: Practice troubleshooting boot issues and managing systemd services .
- Days 6–10 (Scripting for Automation): Pick Python or Bash. Focus on writing scripts that parse logs or check system health. Task: Write a script that checks disk space and emails you if it’s above 80%.
- Days 11–15 (SRE Theory): Read the Google SRE Book (the first few chapters are crucial). Task: Define what “Reliability” means for your current company’s main application.
Phase 2: Networking & Cloud Native Ops (Days 16–30)
Focus: How systems talk to each other and where they live.
- Days 16–20 (Advanced Networking): Understand HTTP/S, DNS, TCP/IP, and Load Balancing algorithms. Task: Configure Nginx as a reverse proxy and load balancer.
- Days 21–25 (Containerization & Orchestration): Deep dive into Docker and Kubernetes concepts (Pods, Services, Deployments). Task: Deploy a stateless app on a local Kubernetes cluster (Minikube/Kind).
- Days 26–30 (Cloud Infrastructure): Review AWS/Azure basics relevant to ops (VPC, IAM, Storage). Task: Use Terraform (Infrastructure as Code) to spin up a small test environment.
Phase 3: The Observability Deep Dive (Days 31–45)
Focus: Making the invisible visible.
- Days 31–35 (Monitoring with Prometheus): Install Prometheus. Understand Exporters (Node Exporter, Blackbox Exporter). Task: Scrape metrics from your local Linux machine and query them using PromQL .
- Days 36–40 (Visualization with Grafana): Connect Grafana to Prometheus. Learn to build meaningful dashboards, not just pretty ones. Task: Create a “Golden Signals” dashboard (Latency, Traffic, Errors, Saturation).
- Days 41–45 (Logging & Tracing): Explore the ELK Stack (Elasticsearch, Logstash, Kibana) or Loki. Task: Set up a centralized logging agent to capture logs from your Docker containers.
Phase 4: Reliability in Action (Days 46–55)
Focus: Performance, Chaos, and Incident Management.
- Days 46–48 (SLIs, SLOs, and Error Budgets): Learn the math. How do you calculate 99.9% availability? Task: Draft an SLA document for a hypothetical login service .
- Days 49–52 (Performance Engineering): Use JMeter to stress test an application. Task: Break your local app. Find the breaking point where latency spikes.
- Days 53–55 (Incident Response): Study “On-Call” best practices. Learn how to write a blameless post-mortem. Task: Simulate an outage and write a report on how you fixed it and how to prevent recurrence.
Phase 5: The Final Sprint (Days 56–60)
Focus: Assessment and Review.
- Days 56–58 (Capstone Project): Combine everything. Deploy an app, set up monitoring, define an alert, and automate a recovery script.
- Day 59 (Mock Exams): Take practice tests to get comfortable with the question format. Review weak areas.
- Day 60 (Rest & Readiness): Review your notes. Ensure your environment is ready for the exam. Relax.
Common Mistakes to Avoid
- Ignoring Culture: Focusing only on tools (like Grafana) without understanding the cultural shift of “blameless post-mortems.”
- Over-Alerting: Creating too many alerts leads to “alert fatigue,” causing critical issues to be ignored.
- Confusing SLAs and SLOs: Failing to understand the difference between the internal objective (SLO) and the external agreement (SLA).
- Neglecting “Toil”: Failing to identify and automate manual tasks, which is a core tenet of SRE.
Best Next Certification
- Certified DevOps Architect (CDA): To broaden your scope from reliability to the entire architectural lifecycle.
Choose Your Path
The tech world is vast. Depending on your interest, you can pivot your career in six distinct directions after mastering SRE basics.
- The DevOps Path: Focuses on CI/CD, Culture, and Collaboration to bridge the gap between code and deployment. Key Cert: Master in DevOps.
- The DevSecOps Path: Focuses on security integration, compliance, and vulnerability scanning to “Shift left” on security. Key Cert: Certified DevSecOps Professional.
- The SRE Path (You are here): Focuses on Reliability, Scalability, and Observability to keep the system running at 99.99%. Key Cert: SRECP.
- The AIOps/MLOps Path: Focuses on AI-driven operations and model deployment to automate remediation using Machine Learning. Key Cert: Certified MLOps Engineer.
- The DataOps Path: Focuses on data pipelines, ETL, and data quality to deliver reliable data to business teams faster. Key Cert: Certified DataOps Professional.
- The FinOps Path: Focuses on cloud cost optimization and budgeting to maximize business value from cloud spend. Key Cert: Certified FinOps Practitioner.
Role → Recommended Certifications
For managers and engineers, knowing which certification aligns with your job title is critical for career growth.
| Role | Recommended Certification |
|---|---|
| DevOps Engineer | Master in DevOps / SRECP |
| Site Reliability Engineer | SRECP (Primary) / Certified Kubernetes Administrator (CKA) |
| Platform Engineer | SRECP / Certified DevOps Architect |
| Cloud Engineer | AWS/Azure Solutions Architect / SRECP |
| Security Engineer | Certified DevSecOps Professional |
| Data Engineer | Certified DataOps Professional |
| FinOps Practitioner | Certified FinOps Practitioner |
| Engineering Manager | SRECP (for technical oversight) / Certified DevOps Manager |
Top Training Institutions for SRECP
The following institutions are recognized for providing training and certification help for the SRECP program:
- DevOpsSchool: The official provider of the SRECP. Known for its community-driven approach, experienced trainers, and comprehensive curriculum that blends theory with deep hands-on labs .
- Cotocus: A consultancy-focused group that offers specialized training modules often tailored for corporate upskilling in SRE and DevOps domains.
- Scmgalaxy: A long-standing community portal for SCM and DevOps professionals that provides resources, tutorials, and guidance for reliability engineering.
- BestDevOps: Focuses on curating top-tier DevOps resources and training paths for working professionals.
- devsecopsschool: While focused on security, they offer foundational modules that overlap with SRE, particularly in secure infrastructure reliability.
- sreschool: A niche platform dedicated specifically to Site Reliability Engineering disciplines and roadmaps.
- aiopsschool: Focused on the intersection of AI and Ops, often covering advanced SRE topics like predictive monitoring.
- dataopsschool: Provides training on data reliability, which is a critical subset of modern SRE work.
- finopsschool: Teaches the economic aspect of reliability, helping SREs understand the cost implications of their architecture.
General FAQs
1. Is SRE harder than DevOps?
SRE is not necessarily “harder,” but it is more specialized. It requires a deeper understanding of coding and system internals compared to a generalist DevOps role.
2. How much time does it take to prepare?
For a working professional, a dedicated period of 30 to 45 days (spending 2 hours daily) or 60 days (1 hour daily) is sufficient.
3. Do I need to know coding?
Yes. You don’t need to be a full-stack developer, but you must be comfortable with scripting (Python, Go, or Bash) to automate tasks.
4. What is the value of this certification?
It validates your ability to manage high-scale systems. Companies pay a premium for engineers who can guarantee uptime and performance.
5. What are the prerequisites?
A solid understanding of Linux administration and basic networking is essential. Experience with a public cloud (AWS/Azure) is helpful.
6. Does this cover Kubernetes?
Yes, modern SRE is heavily reliant on Kubernetes. The course covers orchestration concepts vital for reliability .
7. Is this suitable for freshers?
While possible, it is recommended for professionals with at least 1-2 years of experience in IT operations or development for maximum benefit.
8. How does this help my career?
SREs are among the highest-paid technical roles. This certification proves you have the specific mindset required for these high-stakes positions.
9. Can I take this if I am a manager?
Absolutely. Managers need to understand Error Budgets and SLOs to effectively negotiate with product teams and protect their engineering staff.
10. Is the exam practical or theoretical?
The SRECP focuses on practical application. You will be expected to understand how to apply concepts to real scenarios, not just memorize definitions.
11. What tools will I learn?
You will gain exposure to Prometheus, Grafana, ELK Stack, JMeter, and various automation tools that are industry standards.
12. What happens if I fail?
Most providers offer a retake policy or mentorship to help you identify weak areas and succeed on the next attempt.
SRECP Specific FAQs
1. Who provides the SRECP Certification?
The SRECP is officially offered by DevOpsSchool, a leader in DevOps and SRE training .
2. Is the training live or recorded?
DevOpsSchool offers both options. You can choose “Live & Interactive” online batches for direct mentor interaction or “Self-learning” video modes if you prefer your own pace.
3. Does the course include a project?
Yes. To verify your skills, you are required to work on one real-time scenario industry-based project that aligns with the curriculum modules.
4. What happens if I miss a live class?
Recordings of live classes are uploaded to the LMS. You also have the option to attend the missed session in a future batch within 3 months.
5. Is there a refund policy?
Strictly speaking, no. Once training is confirmed, there is no refund. However, if you have a genuine reason for discontinuing, you may be allowed to join a later batch.
6. Do I get lifetime access to materials?
Yes. You get lifetime access to the Learning Management System (LMS), which includes class recordings, presentations, notes, and step-by-step guides .
7. Does this certification help with interviews?
Yes. The program includes a complete “Interview Kit” crafted from industry experience to help you prepare for the SRE hotseat.
8. Can I get a discount?
Group discounts are available. Typically, groups of 2-3 students can get a 10% discount, and larger groups can negotiate higher percentages.
The Final Verdict
Reliability is no longer a “nice-to-have” feature; it is the single most critical metric for any digital business. When Instagram goes down, the world knows instantly. As an engineer or manager, your ability to prevent those outages—or fix them in seconds—is what defines your value in the market. The Site Reliability Engineering Certified Professional (SRECP) is more than just a badge on your LinkedIn profile. It is a rigorous validation that you possess the engineering discipline to tame complex systems. It moves you from a reactive “fire-fighting” role to a proactive “fire-proofing” career.